
科技动态
 打印
打印近日,中国科学院上海高等研究院(以下简称“上海高研院”)祝永新研究员和黄尊恺副研究员团队与上海科技大学王春东研究员合作,在通用矩阵乘法加速器领域取得重要进展,提出了一种名为Bit-Cigma的创新硬件架构。该架构通过优化比特稀疏性和重构浮点运算流程,成功突破了现有矩阵乘法加速器设计中的技术瓶颈。相关成果已于2025年2月发表于计算机体系结构领域的顶级期刊IEEE Transactions on Computers。
矩阵乘法是人工智能与科学计算的核心基础,广泛应用于神经网络训练、复杂系统模拟等关键任务。这些领域对计算能力的要求极高,需要在处理浮点数运算和量化整数运算时具备出色的性能和精度。然而,现有矩阵乘法加速器设计长期面临两大挑战:其一,二进制数据表示中的比特级冗余导致计算资源浪费,成为计算效率的瓶颈;其二,浮点数对阶依赖高延迟、重资源的方法,成为吞吐量与计算精度的瓶颈。
针对上述挑战,Bit-Cigma架构通过一系列创新技术实现了重大突破。该架构是一种可扩展的比特稀疏感知架构,能够灵活支持多种数据类型,为各类矩阵乘法任务提供卓越的性能、精度和效率。研究团队提出了一种紧凑型规范有符号数(CCSD)编码技术,以减半于传统方法的硬件成本实现高效片上稀疏化,通过最大化比特稀疏性显著削减冗余计算。针对大规模矩阵运算,团队设计了分段式处理方法,将矩阵分解为大小合适的数据块并动态执行浮点数对阶,从而在避免增加硬件资源的同时确保计算零误差,大幅提升处理速度与吞吐量。
大量实验表明,基于CCSD的Bit-Cigma架构相比当前最先进的浮点数和量化整数加速器,性能提升3-4倍,能效提高超过10倍,且实现了其他加速器无法达到的零计算误差。Bit-Cigma架构和CCSD技术为通用矩阵乘法提供了更高效、高性能的解决方案,有望支持各种应用,并为未来的以硬件为中心的高性能系统奠定基础。
该研究工作由上海高研院团队牵头完成,得到了国家重点研发计划、国家科技部SKA专项、国家工信部高质量专项和上海市人才发展基金等项目的资助支持。
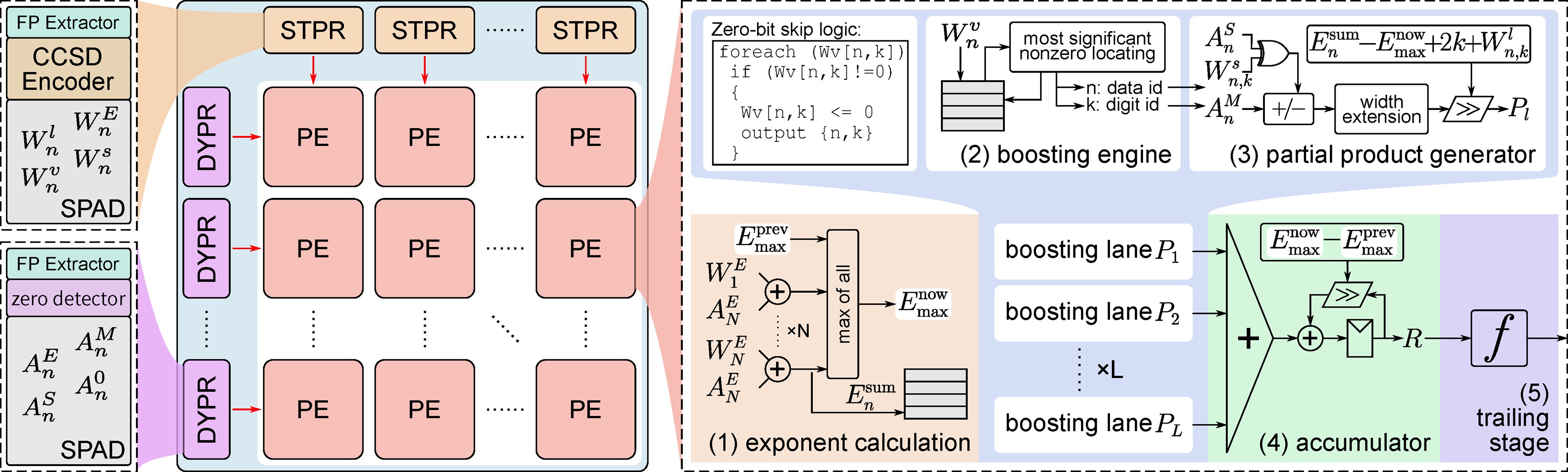
图1:论文中提出的Bit-Cigma 矩阵乘法加速架构